openmp学习笔记 主要参考这两篇博客:https://blog.csdn.net/ArrowYL/article/details/81094837 https://blog.csdn.net/YUNXIN221/article/details/103964460
几种常用的子句 openmp 指令一般以 #pragma omp 开头,后面接其他的子句。常用子句有:
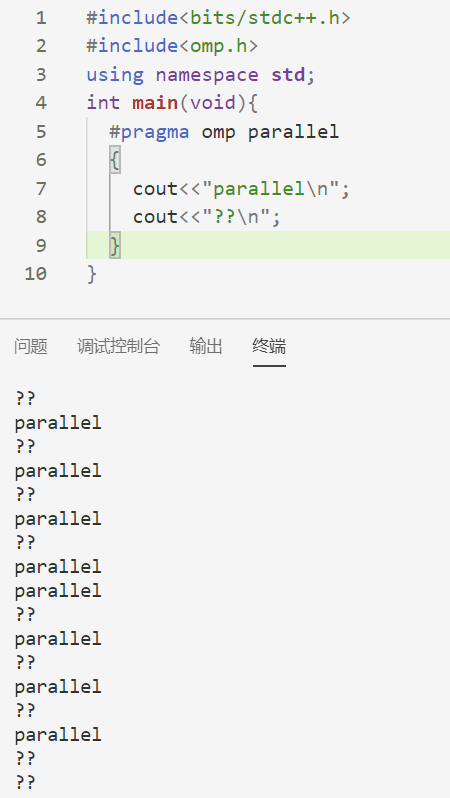
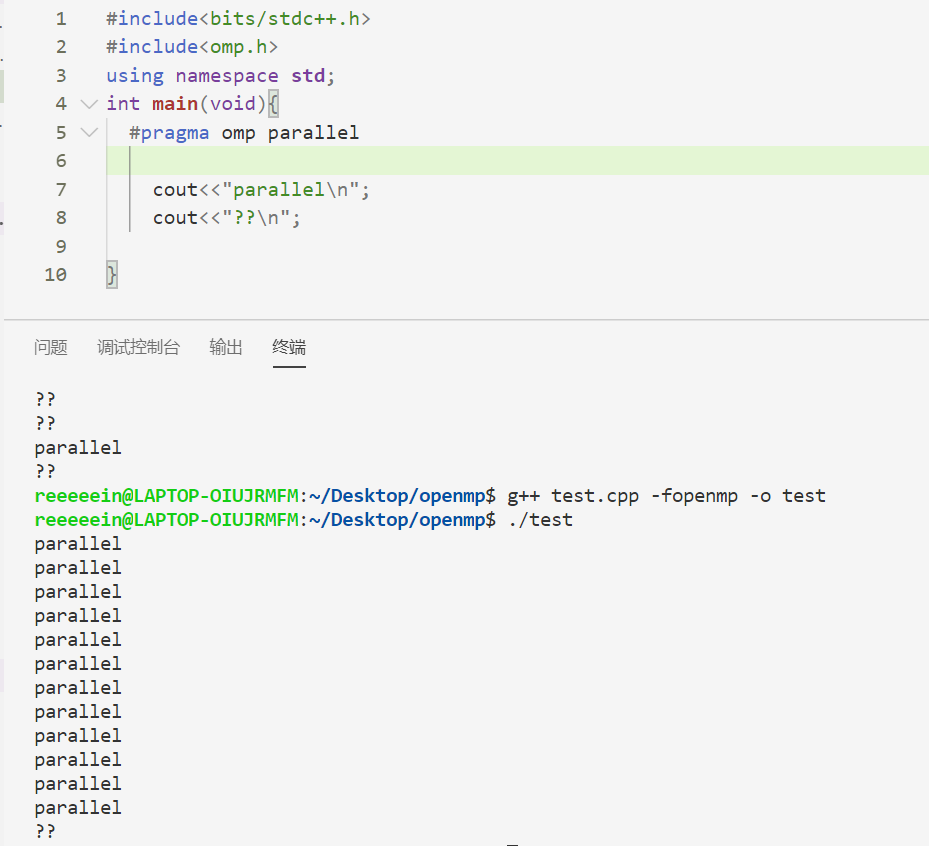
parallel 用于指定接下来的代码块被并行执行,如
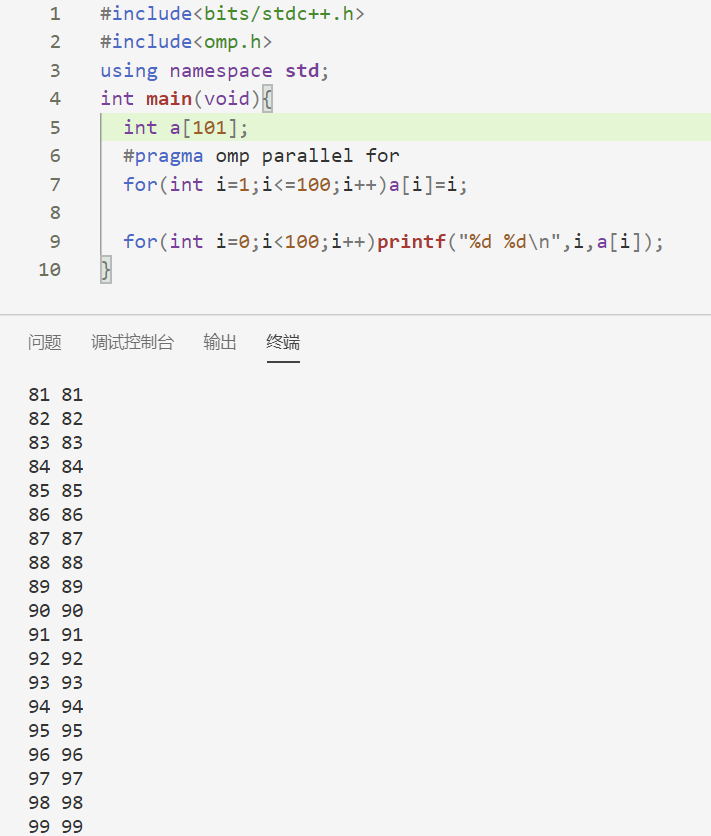
for for子句一般与parallel一起用,可以使一段for循环被分配到多线程处理。注意,用户需要保证for循环中没有数据依赖问题,否则会得到错误结果。
错误示范:
1 2 3 4 5 6 7 8 9 10 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int main (void ) int fib[101 ]={1 ,1 }; #pragma omp parallel for for (int i=2 ;i<=20 ;i++)fib[i]=fib[i-1 ]+fib[i-2 ]; for (int i=0 ;i<=20 ;i++)printf ("%d " ,fib[i]); }
结果为
此外,需注意的是使用for子句还对for循环有很多要求:
sections和section sections 子句将每个section分给一个线程执行,不同section之间是并行的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <bits/stdc++.h> #include <omp.h> int main (void ) #pragma omp parallel sections { #pragma omp section { printf ("section 1 threadid=%d\n" ,omp_get_thread_num()); } #pragma omp section { printf ("kjaenknfe\n" ); } #pragma omp section { printf ("section 3 threadid=%d\n" ,omp_get_thread_num()); } #pragma omp section { printf ("section 4 threadid=%d\n" ,omp_get_thread_num()); } } }
private,firstprivate,lastprivate private(x)子句为每个线程声明一个私有变量x,不同线程的x之间没有联系,即使前面的程序中有x这个变量也不会干扰。
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int main (void ) int x=100 ; cout <<"x=" <<x<<endl ; #pragma omp parallel private(x) { x=omp_get_thread_num(); printf ("In thread %d,x=%d\n" ,omp_get_thread_num(),x); } cout <<"x=" <<x<<endl ;}
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int main (void ) int x=100 ; cout <<"x=" <<x<<endl ; #pragma omp parallel firstprivate(x) { x+=omp_get_thread_num(); printf ("In thread %d,x=%d\n" ,omp_get_thread_num(),x); } cout <<"x=" <<x<<endl ;}
运行结果:
在for循环中使用lastprivate:
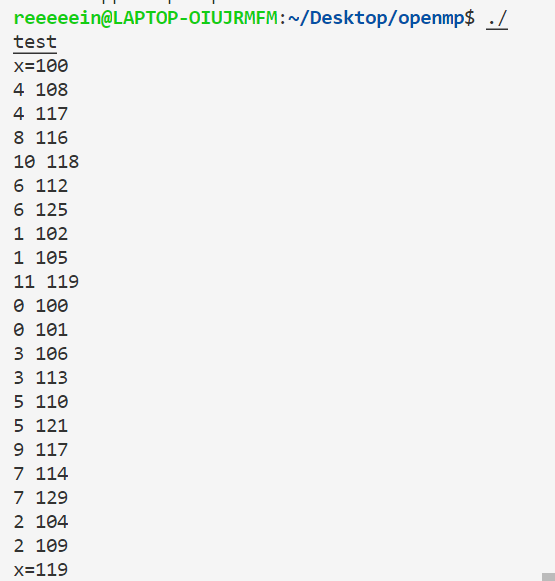
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int main (void ) int x=100 ; cout <<"x=" <<x<<endl ; #pragma omp parallel for firstprivate(x),lastprivate(x) for (int i=0 ;i<20 ;i++){ x+=i; printf ("%d %d\n" ,omp_get_thread_num(),x); } cout <<"x=" <<x<<endl ;}
注意,如果是在for循环中使用lastprivate(x),则会将最后一个线程的x的最终值赋给主变量中的x。这里的最后一个线程指的是逻辑上的最后一个,而不是最后一个结束的,如这里线程号为11的线程是最后一个,它的x的值最终是119,所以把119赋给主程序中的x。
在sections中使用lastprivate:
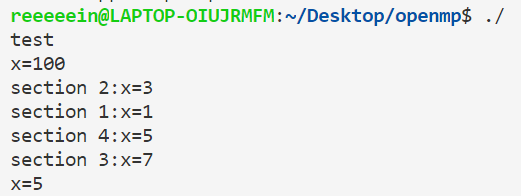
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int main (void ) int x=100 ; cout <<"x=" <<x<<endl ; #pragma omp parallel sections lastprivate(x) { #pragma omp section { x=omp_get_thread_num(); printf ("section 1:x=%d\n" ,x); } #pragma omp section { x=omp_get_thread_num(); printf ("section 2:x=%d\n" ,x); } #pragma omp section { x=omp_get_thread_num(); printf ("section 3:x=%d\n" ,x); } #pragma omp section { x=omp_get_thread_num(); printf ("section 4:x=%d\n" ,x); } } cout <<"x=" <<x<<endl ;}
而如果是在sections里使用,则会把最后一个section的x赋值回去。
threadprivate threadprivate(x)将x(一般是全局变量)复制到各个子线程,在其他线程中修改x的值不会影响主程序中x的值,但第0个线程中修改x的值会导致主程序中x的值一并修改。
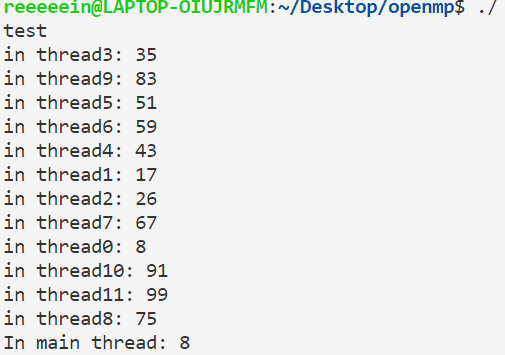
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int global_x = 10 ;#pragma omp threadprivate(global_x) int main (void ) #pragma omp parallel for for (int i=0 ;i<100 ;i++){ global_x=i; } #pragma omp parallel printf ("in thread%d: %d\n" ,omp_get_thread_num(),global_x); cout <<"In main thread: " <<global_x<<endl ;}
运行结果:
copyin copyin(x)等于把threadprivate变量x全局变量广播一遍,让所有线程的x值与主进程相同。
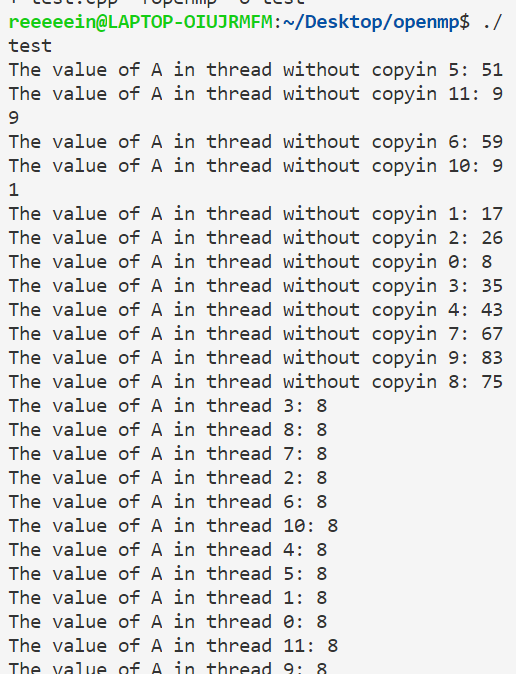
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <omp.h> #include <bits/stdc++.h> using namespace std ;int A=100 ;#pragma omp threadprivate(A) int main (void ) omp_set_dynamic(0 ); #pragma omp parallel for for (int i=0 ;i<100 ;i++){ A=i; } #pragma omp parallel { printf ("The value of A in thread without copyin %d: %d\n" ,omp_get_thread_num(),A); } #pragma omp parallel copyin(A) { printf ("The value of A in thread %d: %d\n" ,omp_get_thread_num(),A); } }
运行结果:
openmp中的任务调度问题 对于一个for循环,编译器要考虑将不同的部分调度给不同的线程执行。默认情况下openmp大多采用静态调度方法,即假设循环需要进行n次,有k个线程,则前$n%k$个线程执行 $\left\lceil\dfrac{n}{k}\right\rceil$次,后$n-n%k$个线程执行$\left\lfloor\dfrac{n}{k}\right\rfloor$次。
OpenMP提供了schedule子句来实现任务的调度。schedule子句格式:schedule(type,[size])。
参数type是指调度的类型,可以取值为static,dynamic,guided,runtime四种值。其中runtime允许在运行时确定调度类型,因此实际调度策略只有前面三种。
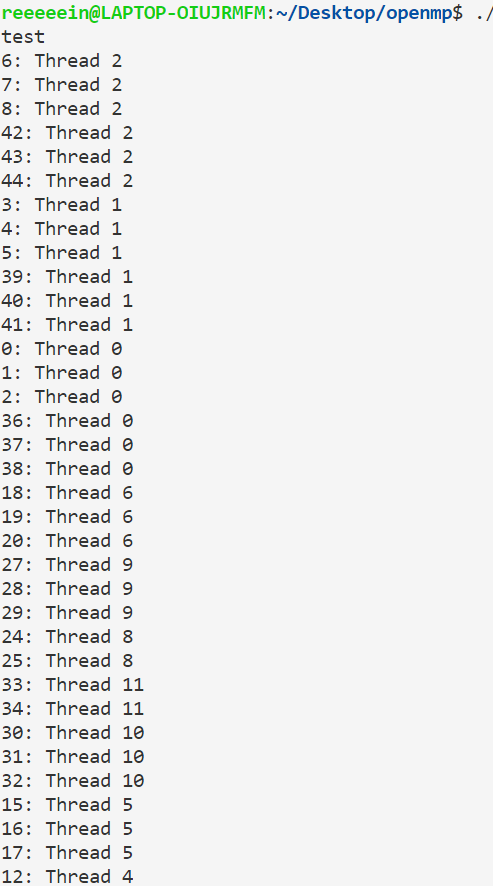
1 静态调度staticsize 次由第二个线程执行……第(k-1) size+1——k*size次由第k个线程执行。如果k*size<n,则再分配size次给第一个线程、分配size个给第二个线程……
1 2 3 4 5 6 7 8 9 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int main (void ) #pragma omp parallel for schedule(static,3) for (int i=0 ;i<50 ;i++){ printf ("%d: Thread %d\n" ,i,omp_get_thread_num()); } }
运行结果:
2 动态调度dynamic
当不使用size 时,是将迭代逐个地分配到各个线程。当使用size 时,逐个分配size个迭代给各个线程,这个用法类似静态调度。
3 启发式调度guided
size表示每次分配的迭代次数的最小值,由于每次分配的迭代次数会逐渐减少,少到size时,将不再减少。具体采用哪一种启发式算法,需要参考具体的编译器和相关手册的信息。
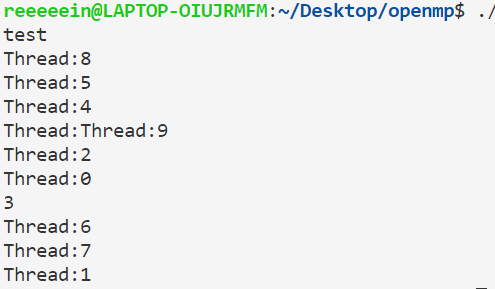
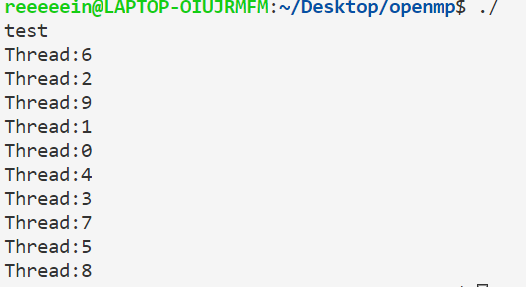
一点小建议 尽量不要用在并行执行的程序块里cout。原因很简单,比如cout<<a<<b,可能第一个线程刚输出了a还没输出b,第二个线程由输出了a,就乱套了,比如下面的例子:
1 2 3 4 5 6 7 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int main (void ) #pragma omp parallel for for (int i=0 ;i<10 ;i++)cout <<"Thread:" <<omp_get_thread_num()<<"\n" ; }
但如果是使用printf就这个问题:
如果要统计一段openmp并行化的程序的运行时间,不要用clock()函数。这是因为clock()得到的是cpu时间,会把多个核的时间加在一起;而我们想要的一般是现实中经过的时间,所以要用omp_get_wtime()函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <bits/stdc++.h> #include <omp.h> using namespace std ;int x;void f () for (int i=0 ;i<300000000 ;i++); } int main (void ) double t1=omp_get_wtime(); #pragma omp parallel for for (int i=0 ;i<12 ;i++)f(); double t2=omp_get_wtime(); cout <<t2-t1<<"s\n" ; double t3=clock(); #pragma omp parallel for for (int i=0 ;i<12 ;i++)f(); double t4=clock(); cout <<(t4-t3)/1e6 <<"s\n" ; }
结果如下: