并行与分布式计算作业1
作业题目
现代处理器如Intel、ARM、AMD、Power以及国产CPU如华为鲲鹏等,均包含了并行指令集合,① 请调查这些处理器中的并行指 令集,并选择其中一种进行编程练习,计算两个各包含10^6个整数的向量之和。 此外,② 现代操作系统为了发挥多核的优势,支持多线程并行编程模型,请将问题①用多线程的方式实现,线程实现的语言不限,可以是Java,也可以是 C/C++。
用串行的方法完成向量之和计算
为了进行对照,先写一个串行的程序:
1 |
|
进行了5次实验,结果如下: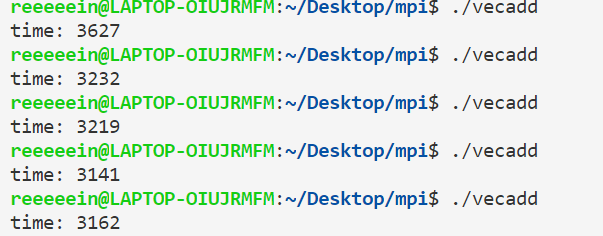
平均耗时:3,276.2μs
用并行指令集axv来完成向量之和计算
首先在https://github.com/chen0031/AVX-AVX2-Example-Code中下载文件夹,在wsl中cd进入文件夹,即可用make命令进行编译,用make run命令运行。
然后执行 cd ./Arithmetic_Intrinsics/src,将其中的add.c文件修改为:
1 | /** |
即可进行计算。
分别进行5次实验,耗时分别为(单位为μs):
1491,1329,1178,2009,1470
平均耗时:1,495.4μs
可以发现,用并行指令集进行计算会快很多,加速比大概是2.19
用多线程来完成向量之和计算
使用mpi来实现多线程完成向量之和,代码如下:
1 |
|
分别对线程数量为3,5,6,9,11(即将数组分为2,4,5,8,10份)进行了实验,结果如下:

可以发现消耗的时间比前面用并行指令集多很多,这应该是因为线程之间通信次数很多,消耗了很多时间,而本身要计算的任务并不复杂,因此多线程的优势并不能得以发挥。
再使用OpenMP来进行多线程计算,这只需将串行的代码稍作修改即可。
代码如下:
1 |
|
对线程数分别为1-11做了5次实验,分别取平均值,绘图如下:
运行结果如下: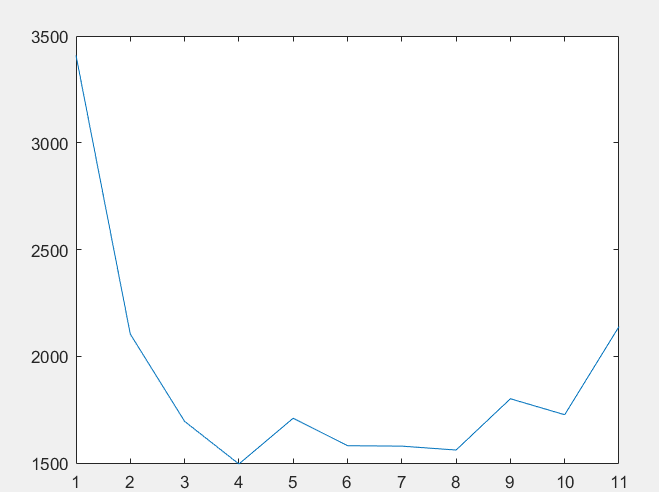
可以看到当线程数为4时,运行时间最短,大概是1500μs,当线程数增多时,运行时间变化并不规律。
绘制对应的加速比图像如下: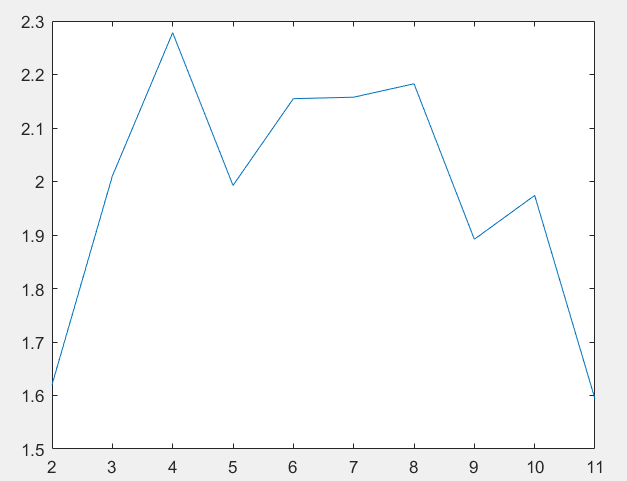
当线程数为4时,加速比大概是2.3,略强于用并行指令集的情况。