fat12文件系统仿真实验报告
实验目的
本实验目的在于学习fat12文件系统,增强编写C语言、C++语言和汇编语言程序的的能力,为进一步学习操作系统相关知识做好准备。
实验要求
总体要求
用c、c++或汇编与c组合,编写一个具有下列功能的可视化或命令操作的FAT12文件系统仿真程序
具体要求
用c、c++或汇编与c组合,编写一个具有下列功能的可视化或命令操作的程序:
1.查看fdd144虚拟软盘的第一个扇区内容是否符合FAT12格式。
2.检查fdd144虚拟软盘的FAT12格式各部分信息是否一致完整。
3.列出fdd144虚拟软盘中根目录文件目录内容。
4.列出fdd144虚拟软盘中目录树。
5.提供一个输入框,输入任意字符,创建一个文件保存这些输入的字符。
6.删除根目录的一个指定文件
7.实现按路径名操作文件
8.显示一个文件的内容
9.编辑文件的内容
10.复制文件,2个文件合并为一个文件。
11.建立子目录
12.删除子目录
13.其他
实验方案与过程
实验环境
首先通过WinImage软件创建一个虚拟软盘,往里面添加文件,保存后得到一个fat12格式的软盘。为了方便验证结果是否正确,我使用了HexView工具来查看软盘的内容。编写代码时,我主要在WSL(一个可以在windows操作系统下运行的linux简化版)系统下使用VSCode编辑器,用c语言和c++语言进行编程。
fat12文件系统相关知识
一块1.44MB的fat12格式的软盘共有2880个扇区,每个扇区512占个字节。其中第0个扇区称为主引导扇区;第1-9扇区为fat表;第10-18扇区是fat表的复制版;第19-32扇区为根目录区;从第33扇区往后为数据区。
字节和扇区在fat12文件系统中是两个相当重要的概念,为此,我们在程序中定义bt这个结构体来表示字节,sector这个结构体来表示扇区。为了方便行文,先给出它们的定义:
1 | typedef struct byte//用byte和bt来表示字节 |
1 | typedef struct Sector |
创建软盘
我们使用WinImage工具创建软盘。
打开WinImage,点击左上角的文件、新建,然后确定,就创建了一块软盘,我们可以往里面添加文件,我随便拖了两个文件进去,结果如下
按ctrl+s,将其保存为vfd文件。
然后就可以通过HexView工具打开它。
引导扇区
引导扇区主要记录了软盘的相关信息和引导扇区程序。启动计算机时,BIOS程序通过读入引导扇区中的引导扇区程序来启动操作系统。引导扇区的内容如下表所示:
(下表主要参考CSDN博客https://blog.csdn.net/begginghard/article/details/7284834?depth_1-utm_source=distribute.pc_relevant_right.none-task&utm_source=distribute.pc_relevant_right.none-task)
|名称|开始字节|长度|内容|参考值|
|–|–|–|–|–|
|BS_jmpBOOT|0|3|一个短跳转指令|0xEB 0x58 0x90|
|BS_OEMName|3|8|厂商名|’ZGH’|
|BPB_BytesPerSec|11|2|每扇区字节数(Bytes/Sector)|0x200|
|BPB_SecPerClus|13|1|每簇扇区数(Sector/Cluster)|0x1|
|BPB_ResvdSecCnt|14|2|Boot记录占用多少扇区|ox1|
|BPB_NumFATs|16|1|共有多少FAT表|0x2|
|BPB_RootEntCnt|17|2|根目录区文件最大数|0xE0|
|BPB_TotSec16|19|2|扇区总数|0xB40|
|BPB_Media|21|1|介质描述符|0xF0|
|BPB_FATSz16|22|2|每个FAT表所占扇区数|0x9|
|BPB_SecPerTrk|24|2|每磁道扇区数(Sector/track)|0x12|
|BPB_NumHeads|26|2|磁头数(面数)|0x2|
|BPB_HiddSec|28|4|隐藏扇区数|0|
|BPB_TotSec32|32|4|如果BPB_TotSec16=0,则由这里给出扇区数|0|
|BS_DrvNum|36|1|INT|13H的驱动器号|
|0|BS_Reserved1|37|1|保留,未使用|
|0|BS_BootSig|38|1|扩展引导标记(29h)|
|0x29|BS_VolID|39|4|卷序列号|
|0|BS_VolLab|43|11|卷标|
|’ZGH’|BS_FileSysType|54|8|文件系统类型|
|引导扇区程序|62|448|引导代码及其他数据|引导代码(剩余空间用0填充)|
|结束标志0xAA55|510|2|第510字节为0x55,第511字节为0xAA|0xAA55|
BIOS程序通过识别结束标志判断该软盘是否符合fat12格式。
在程序中,我们需要将软盘中的第一个扇区读入程序中,并判断它是否符合fat12格式。由于引导扇区本身就是一个扇区,所以定义sector的子类MBR,用以表示一个扇区。
1 | struct MBR:public sector{ |
在程序开始时,我们首先读入MBR,调用init()函数对各个变量进行赋值;再检查它的前三个字节是否为0xeb 0x58 0x90;然后检查各个变量是否符合默认值;最后看结束标志是否为 0xaa55。如果发现问题,则给出提示信息并中止程序。如果检查正确,则调用print()函数输出各项信息。
fat区
fat区共有18个扇区,其中后9个扇区是前9个扇区的副本。fat12文件系统启动时,需要检查这两部分是否一样。我们将前9个扇区称为fat表。从名字中就可以看出,fat表是fat12文件系统的核心。
在fat12文件系统中,文件存储是以簇为单位的,一般情况下,一个簇就是一个扇区,所以下文将簇与扇区划等号。对于一个文件,如果它的大小小于512字节,则在数据区中给它分配一个簇,将它的内容写进这个簇里,然后将fat表中这个簇对应的值(下文会详述这种对应的方式)修改为一个特殊的结束标志。
如果它的大小大于等于512字节呢?首先还是分配簇a,将文件的前512个字节写进簇a里,然后再分配一个簇b,将fat表中簇a对应的值修改为一个值,通过这个值我们能找到b扇区,然后再分配一个簇c,将fat表中簇b对应的值修改为一个值,通过这个值我们能找到簇c……一直这样下去,直至文件结束,将分配的最后一个簇在fat表中对应的值修改为结束标志。
这样,读文件时,只需知道这个文件开始的簇,就可以读下一个簇,下下个簇……直到在fat表里读到结束标志为止。
下图是一个fat表的开头:(这个fat表不是刚才创建的软盘的fat表)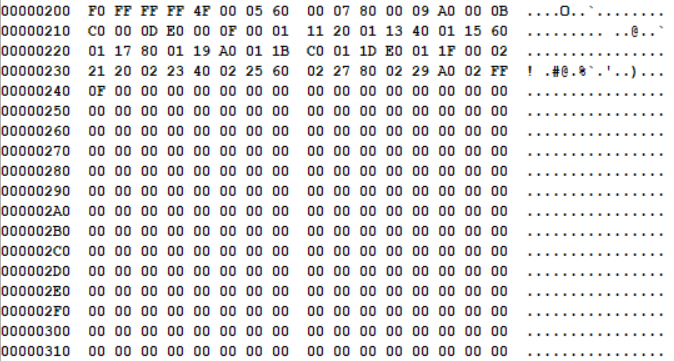
fat12文件系统中的”12”是什么意思呢?12是指一个fat表中12个bit组成一个fat表项,而我们知道一个字节是8个bit,所以fat表中,3个字节组成两个fat表项。
既然如此,fat表该怎么读呢?如果你以为是顺着读,就太naive了。我们知道x86系统采用小端存储方式,就是说,低字节存储在高地址位中(高地址位就是地址值较小)。比如说,一个16位整数0000000011111111,在x86系统中会先存11111111(低字节),再存00000000(高字节)。
了解了这些,我们再来看fat表。前3个字节是 0xf0 0xff 0xff。我们把第二个字节的低四位拿出来,跟第一个字节拼在一起,组成0xff0(注意不是0xf0f),它就是fat表的第一个表项了。再把第三个字节拿出来,和第二个字节的高四位拼在一起,组成 0xfff,它就是第二个表项了,如下图所示:

按这个规则读下去,第三个表项就是0xfff,第四个表项是0x004……
现在我们知道如何读这个fat表了。但问题来了,读出来的值有什么用呢?fat表中读出的第一个值表示坏簇标志,一般为0xff0,第二个值是结束标志,一般为0xfff。后续的每个值代表这个簇的下个簇的簇号。如第三个值为0x004,代表第一个簇(前两个值不算)对应的下一个簇是第二个簇,第四个值为0xfff,表示这个文件到第二个簇这里就结束了。
在程序中,我们定义一个fat结构体:
1 | typedef struct Fat |
程序开始时还是先把fat表读进来,并检查两个fat表是否一致,不一致就报错。然后统计空闲簇和坏簇的数量。
根目录区与数据区
根目录区占14个扇区,由于前面已经用了19个扇区(引导扇区1个,fat18个),所以根目录区是从第19个扇区开始的,起始位置是0x2600。根目录里每32字节构成了一个文件记录,记录了这个文件的基本信息,我们可以根据这个记录来找到文件的内容。
在程序中,我们定义rootentry类来表示根目录区,它比较简单,只有一个bt类型的数组,也不需要检查什么东西。
1 | typedef struct RootEntry |
从第33个扇区往后的扇区都是数据区,每个扇区512字节。定义datas类表示数据区。数据区一般包含2847个扇区,所以定义一个sector数组。
1 | typedef struct Datas |
文件与文件夹
文件的读写是fat12文件系统的重点。我们先来了解文件是怎么组织的。
一个文件会有一个32个字节的文件记录,这个文件记录存储在这个文件所属的文件夹里,包含了这个文件的各种信息:
第1-8个字节是文件名,如果长度不够就用空格填充;
第9-11个字节是文件后缀名,如果长度不够或者没有后缀就用空格填充;
第12个字节是文件属性,十分重要,一般的文件的文件属性就是0x00,文件夹的文件属性一般是0x10。
第13-22个字节是保留字节,没有作用;
第23,24字节是文件的创建时间
第25,26字节是文件的创建日期,精确到分钟
第27,28字节是文件的起始簇号
第29-32字节是文件的大小
我们以根目录为例:
对于第一个文件,它的名字是NEW,后缀名是CPP,文件属性是0x00,说明它是一个普通文件。创建时间是0x89A4,换成二进制是
1000 1001 1010 0100。
其中前5位是小时,10001=17,说明创建时间是17点;后6位是分钟,001101=13,说明具体时间是17:13。后五位没有作用(因为5位最多表示32个数,而一分钟有60秒)
创建日期是0x507E,换成二进制是
0101 0000 0111 1110
前7位是年份与1980的差值, 01010000=40,40+1980=2020,说明文件创建于2020年;后面4位是月份,0011是3,说明是2020年的3月;后面5位11110=30说明日期是 2020-3-30
起始簇号是0x0002
大小是0x0000003c,说明它一共占60个字节。
现在我们知道了这个文件的基本信息,我们要怎么找到它的内容呢?这就需要我们看一下数据区了。
从第33个扇区往后的扇区都是数据区,每个扇区512字节。上文的NEW.CPP文件的起始簇号是2,由于fat表前两个值有其他用途,所以簇号2代表的是第一个簇,或者说数据区的第一个扇区。
数据区的起始位置是0x4200,我们看看这里有什么: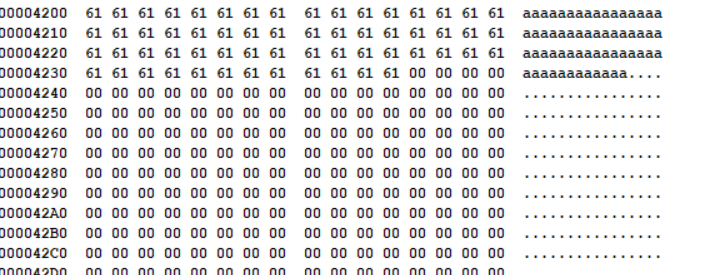
是60个a。
再来看根目录下的下一个文件,起始簇号是3,代表它开始于数据区的第一个扇区,即0x4400
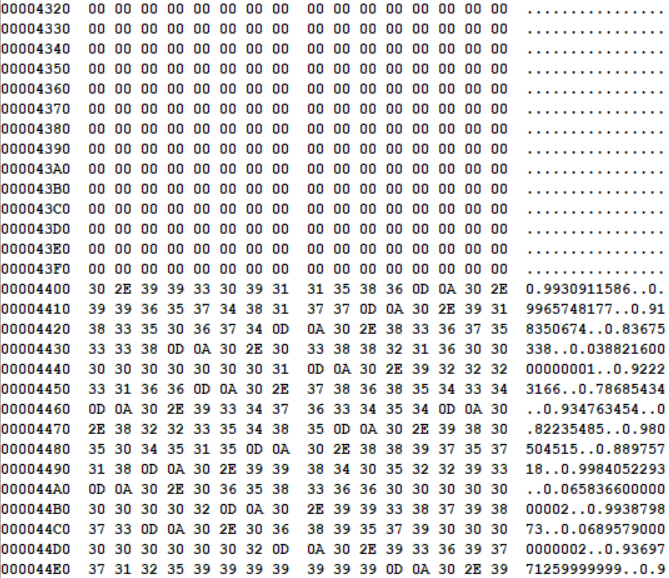
它是一些奇奇怪怪的东西。
根据前文所述的读文件方法,我们可以把整个文件读出来,在此不再赘述。
打开前面创建的软盘,点击上方的映像、创建文件夹,然后输入名字,就可以创建一个文件夹了。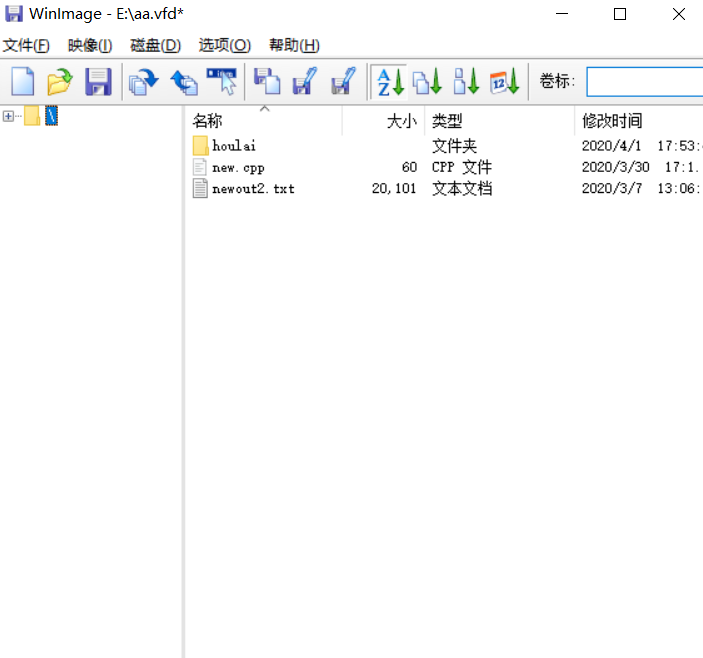
往里面拖两个文件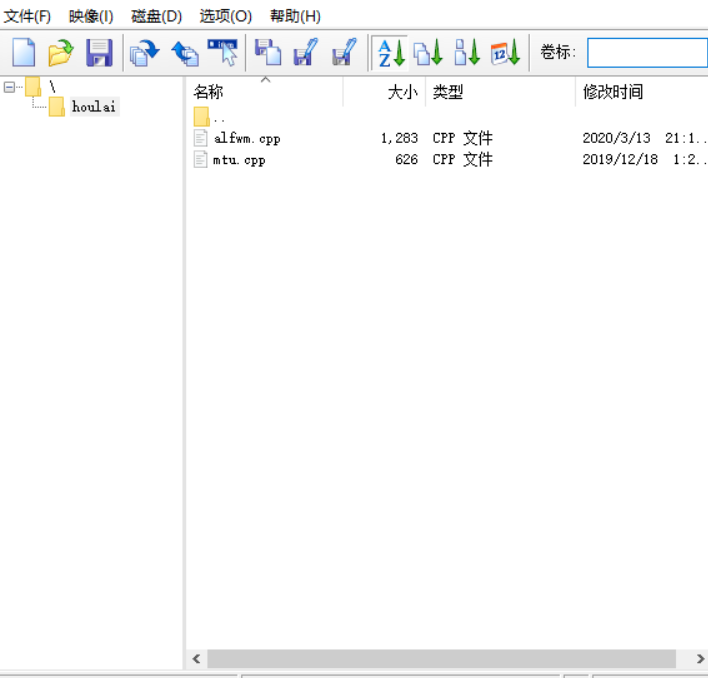
然后我们来看看根目录里发生了什么:
可以看到它多了一个文件记录,名字是HOULAI,后缀是空的,文件属性是0x10,说明这是个文件夹,首簇号是0x2B,由于(0x2B-0x2)*0x200+0x4200=0x9400,我们只需要找到这个地址
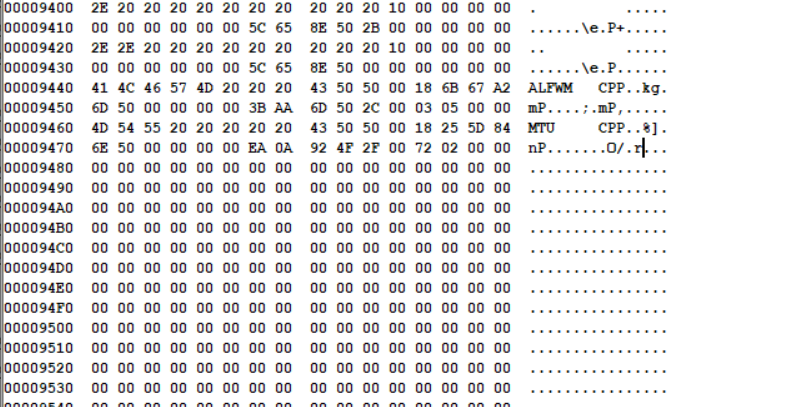
可以看到,这里也是一个个文件记录,其中有两个比较奇怪,第一个文件记录的名字是”.”,第二个文件记录的名字是”..”。事实上,除了根目录之外的每个文件夹都有这两个记录,”.”表示的是当前文件夹,”..”表示的是上一级文件夹。在程序中读取文件时它们会被忽略。
了解了文件和文件夹的存储原理,在程序中读入文件的方法也就很简单了。
在程序中,我们把文件和文件夹统一看成文件,用file类来表示它:
1 | typedef struct File |
具体实现
本系统完成了要求的所有功能,此外还增加了find功能,具体情况请看下表:
| 指令 | 功能 | 备注 |
|---|---|---|
| help | 输出提示信息 | 无 |
| quit | 退出系统 | 无 |
| cd [相对路径或绝对路径] | 进入指定的文件夹 | “..”表示上一级文件夹,”.”表示当前文件夹,用’/‘作分隔符 |
| dir | 展示当前文件夹下的文件信息 | 会输出名字、后缀、修改时间和大小 |
| dir_r | 递归的展示当前文件夹下的所有文件 | 只能看到名字和后缀 |
| print [相对路径或绝对路径] | 输出文件内容 | 目标文件不能是文件夹 |
| gedit [相对路径或绝对路径] | 进入文本编辑器模式,编辑指定的文件 | 无 |
| mk [文件名] [文件内容] | 在当前路径下创建一个文件 | 文件名长度不能超过8,文件名不能包含非法字符,文件要有后缀,不能与已有文件同名 |
| mkdir [文件夹名] | 在当前路径下创建一个文件夹 | 文件夹名长度不能超过8,文件夹名不能包含非法字符,不能与已有文件夹重名 |
| rm [相对路径或绝对路径] | 删除一个文件或文件夹 | 删除操作不可逆,请谨慎操作 |
| find [相对路径或绝对路径] | 根据路径查找文件(夹) | 支持通配符’‘和’?’。’‘可以表示任意长度的字符串,’?’可以表示任意字符。系统会输出所有可能的路径 |
| cp [相对路径或绝对路径][文件夹的相对路径或绝对路径] | 复制文件(夹) | 将第一个参数复制到第二个参数指向的文件夹处 |
| mv [相对路径或绝对路径][文件夹的相对路径或绝对路径] | 剪切文件 | 将第一个参数剪切到第二个参数指向的文件夹处 |
由于许多操作都需要按路径名找到文件,所有我们先来了解按路径名寻找文件的方法:
路径分析
我们在file类中定义了一个map<string,file*>类型的成员变量sons,不用我说也能知道它的作用是什么。
在创建一个文件时,如果它是一个文件夹,则对应它的所有子文件,往sons里加入一个(pair){文件名+”.”+后缀,指向该文件的指针}。这样,我们就能很轻松地根据文件名和后缀找到对应的文件。
我们定义path_analysis和path_analysis2函数。path_analysis2函数接受一个字符串,将它用’/‘分隔为一个字符串向量并返回。
用户输入路径可以是绝对路径或相对路径,当第一个字符为’/‘时,我们认为这是绝对路径,从根目录开始找;否则认为这是相对路径,从当前文件夹下开始找。
从根目录开始找的方法是:
设输入字符串向量为vec,根文件夹指针为f1。
遍历向量的每一个元素,查找f1的sons里是否有子文件(夹)的名字与之匹配,若有则修改f1为对应文件(夹),否则直接返回NULL。
遍历完向量之后说明f1已经是需要的文件(夹),返回f1即可。
1 | file *path_analysis(string input, file *now, file *root) |
从当前目录开始找的方法与此基本相同,不再赘述。
cd操作的实现
既然了解了路径分析的方法,cd操作的实现也就呼之欲出了。我们在程序中定义两个指针,一个名为tem,指向当前所在的文件;一个名为root,指向根文件夹。只需要根据这两个指针和输入的字符串调用paht_analysis函数即可,如果函数返回NULL则报错,否则修改tem。
代码如下:
1 | else if (a == "cd") |
dir操作的实现
进行dir操作时,我们遍历sons,输出所有子文件(夹)的信息,包括文件名、后缀、修改时间和大小。由于这个操作十分简单,代码就不必展示了。
dir_r操作的实现
这个操作的实现需要用到递归的思想。
定义dir_recusive()函数,它返回一个字符串向量。它的实现方法是:
创建一个vector
遍历sons的每一个键值对,如果值(即file指针)指向一个普通文件,则把对应的键放进ret里;
如果指向的是一个文件夹,则对它调用dir_recusive(),把返回的字符串向量的每一个元素加上一个前缀” “,都放进ret里。
为什么要加入一个前缀呢?想一想,当前文件夹下的文件名没有前缀,下一级文件夹下的文件名有一个前缀,再下一级文件夹下的文件名有两个前缀……这样看起来不就形成了树的结构吗?
dir_recusive()函数代码如下:
1 |
|
print操作的实现
这个操作很简单,根据输入的路径找到相应的文件夹,然后输出它的内容即可。
mk操作的实现
这个操作是重点和难点。首先我们要根据第一个参数找到文件夹,根据第二个参数创建一个文件。怎么创建一个文件?
我们知道文件是保存在数据区里的,那我们要在数据区里找到一个空闲的扇区,这可以在fat表里找(也可以用已删除的文件占用的扇区,这会在下文讲解)一个空闲簇号,找到之后将内容写到对应的扇区,将fat表对应的位置修改为一个结束标志。如果文件内容不止512个字节,则继续分配一个簇号,将内容写进去,将fat表中上一个簇号对应的位置修改为一个这个簇号,将这个簇号对应的文职修改为一个结束标志。一直这样下去,直到写完为止。
这部分代码如下:
1 | while (!Content.empty()) |
创建文件的其他操作就很简单了,注意要设置fa指针指向父文件夹。此外还要给文件生成一条文件记录,把它添加进父文件夹的内容里,给父文件夹的sons变量添加一个键值对。最后把fat表更新一遍。
mkdir操作的实现
搞定了mk操作后,mkdir也就差不多了。区别是创建出来的文件的内容是两条文件记录,记录”.”和”..”这两个”子”文件夹。
rm操作的实现
rm操作可能是最难的操作了。
我们定义一个queue<pair<file , int>>类型的全局变量deleted_clusters。它的每一个元素是一个 file,int 对。
当我们删除某个文件夹下的一个文件时,我们将它的文件记录的第一个字符变成一个删除标志,同时需要将 指向文件夹的指针 和 这个文件记录的序号 组成一个pair,push进deleted_clusters里。
这样做有什么好处呢?假设我们在删除操作完成后就退出系统,然后重新打开,读入文件夹时,我们如果读到一个首字符为删除标志的文件记录,就把指向文件夹的指针和文件记录的序号放进deleted_clusters里。
此后,如果我们需要再创建一个文件,就可以去deleted_clusters找被删除的簇。怎么找呢?我们先通过deleted_culsters的front()方法得到一个pair,根据它找到之前删除文件的文件记录,它不是记录了这个文件在数据区的位置了吗?直接将这些位置覆盖就可以了。覆盖完之后将这个pair pop掉就可以了。
这样就大功告成了吗?还没有,至少还有两个问题:
1.如果被删除的文件占用两个扇区,而我这次创建的文件只有一个扇区,那我把删除文件的首扇区覆盖了,第二个扇区不就成了孤魂野鬼了?
2.将被删除文件的内容覆盖了之后,我们并没有修改它的文件记录,这样,我们下一次启动系统,还是会将它对应的pair读到deleted_clusters里,这样就可能又把它覆盖了一遍,不是就乱套了吗?
其实解决方法也很简单。
第一个问题,只需将首扇区覆盖之后,看一下这个扇区在fat表中对应的值是否是结束标志,如果不是,就修改文件记录,使它的首扇区变成原来的第二个扇区。同时,由于这个文件还没有被完全覆盖,因此不必在deleted_clusters里把它对应的pair pop掉。
第二个问题,只需要将文件记录里的首扇区标志改为0,此后读文件时遇到这种首扇区标志位0的文件记录就跳过即可。
以上就是删除普通文件的基本方法。删除文件夹呢?也很简单,递归地把子文件都删除,再将文件夹也删除了就可以了。
为什么要这样?因为我的deleted_clusters是一个队列,由于子文件先删除,队列又是先进先出的,覆盖的时候便会先覆盖子文件,再覆盖文件夹。否则要是先把文件夹覆盖了,子文件的文件记录找不到了,就出现”孤魂野鬼”了。如果deleted_clusters是一个栈,就应该先删除文件夹,再删除文件。
删除操作的代码如下:
1 | void File::remove() |
gedit操作的实现
为了实现这个操作,我设计了一个简易的编辑器。它的原理是不断相应键盘的输入,每输入一次就把控制台刷新一次,然后输出。由于这个编辑器与fat12文件系统关系不大,我就不再赘述。
这个操作也是根据输入的字符串找到相应的文件(注意这个文件不能是文件夹),然后调用编辑器编辑它的内容,当用户按下ctrl+s则将修改后的内容保存回去。怎么保存呢?很简单,只需把原来的文件删掉,再创建一个同名而不同内容的文件即可。
find操作的实现
find操作本事不算复杂,但为了使我的文件系统更有特色,我给它增加了’*’和’?’这两个通配符。
’‘表示任意字符串(甚至可以是空的)。比如 “houlai”和”h\lai”是匹配的。
’?’表示单个字符。比如”zhiqian”和”?hi?ian”是匹配的。
怎么实现字符串的带通配符匹配呢?一种方法是暴力法,即直接枚举通配符的每一种可能。但这样效率很低,在字符串很长的情况下根本配不出来。
另一种是动态规划法,即dp(dynamic planning),对输出长度为n和m的字符串,它的时间复杂度是O(nm)的,效率很高。由于这部分内容与fat12文件系统关系不大,具体的dp方法就不必赘述,直接给出匹配的代码:
1 | bool isMatch(string a, string b){ |
搞定了单个字符串的匹配方法,find操作的实现也就简单了,只需像之间路径分析一样搜索下去,找到了就将路径放进一个vector<string>里。不同的是这里的find可以找到多个路径,因此需要用dfs的方法;而之前的路径分析最多只有一个结果,因此直接找就可以了。
具体代码如下:
1 | void File::find_string(int loc, vector<string> &b, vector<string> &ret) |
cp操作和mv操作
在明确了如何找文件,如何删除文件之后,这两个操作也就非常简单了,没有进行解释的必要。
代码架构
总共有12个文件,分别是:
| 文件名 | 内容 |
|---|---|
| fun.cpp | 定义了各种通用的函数 |
| byte.h | 定义了byte类 |
| byte.cpp | byte类的实现和与之相关的函数 |
| sector.h | 定义了sector类和它的实现 |
| mbr.h | 定义了MBR类 |
| mbr.cpp | MBR类的实现 |
| file.h | 定义了file类、fat类、rootentry类和datas类。 |
| file.cpp | 上述几个类的实现和相应的函数。 |
| getch.cpp | 定义了一个函数 |
| my_editor.h | 定义了my_editor类和一些函数 |
| interface.cpp | 给出了my_editor类的大部分实现,定义了一些与用户交互的函数 |
| main.cpp | 包括了程序开始时的检查和根文件夹的读入 |
总计约1900行代码
结果展示
使用dir_r可以展示目录树: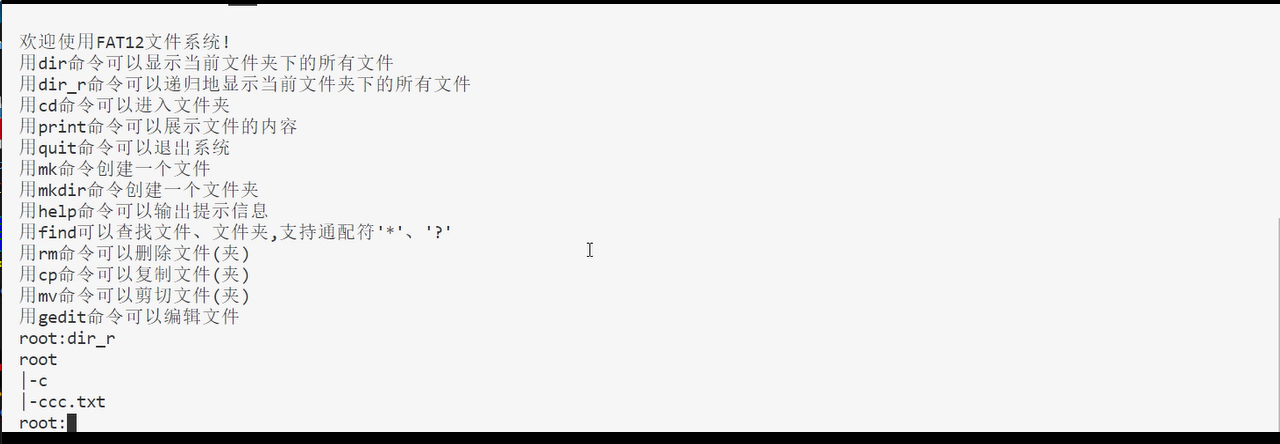
使用print可以显示文件内容: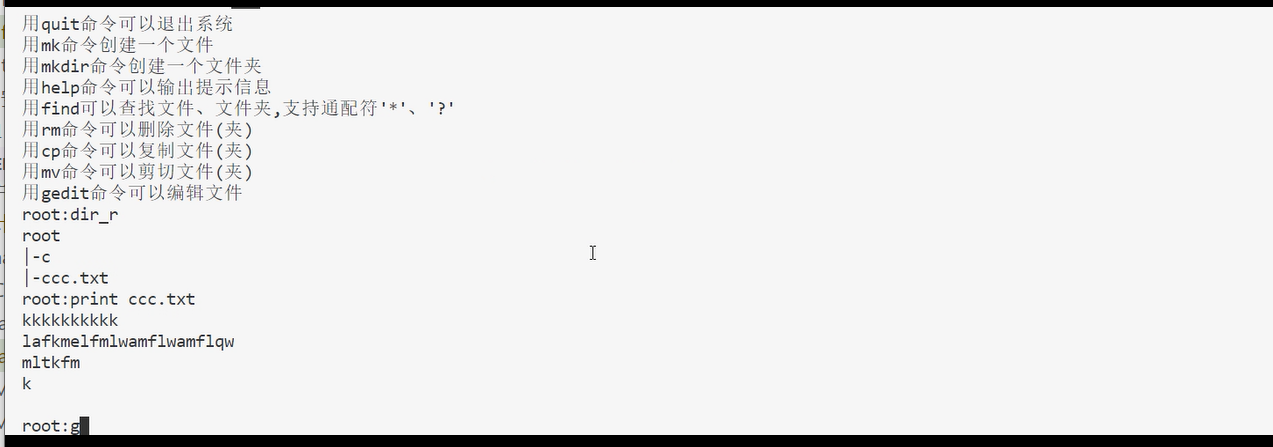
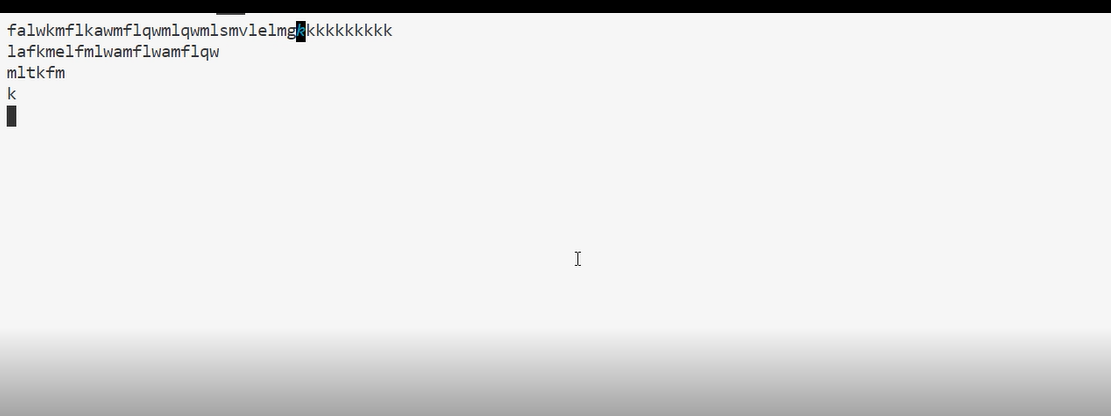
使用gedit可以编辑文件: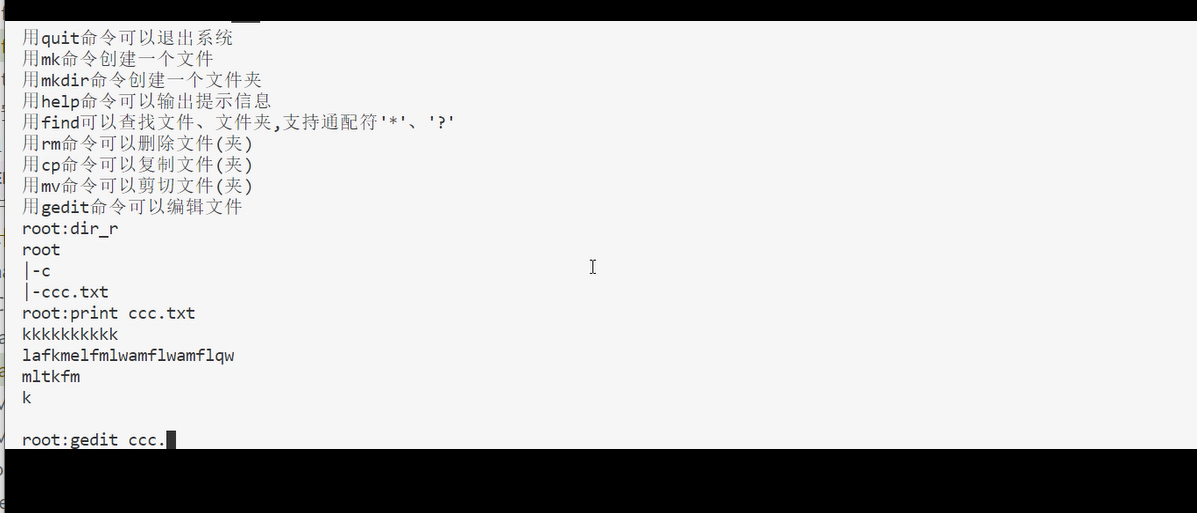
使用dir命令可以查看当前文件夹下的内容:
使用cd命令可以进入文件夹:
使用mk命令可以创建文件,使用rm文件可以删除文件:
使用mkdir命令可以创建文件夹:
使用cp命令可以复制文件: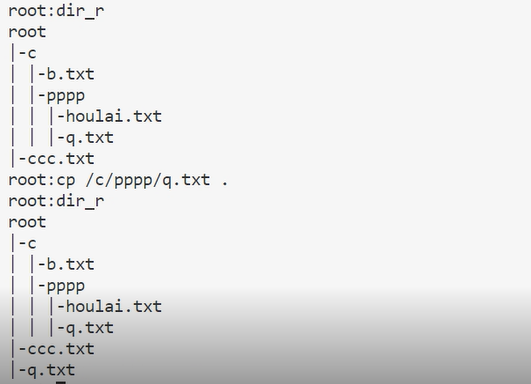
使用mv命令可以剪切文件: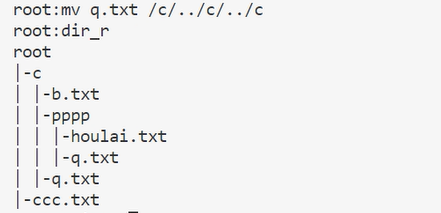
使用rm命令还可以删除文件夹:
详情请看演示视频。
实验总结
这次实验可以说是我做过最难的实验了,代码量大,编程难度高,还用到了搜索、动态规划等算法。但从最后的完成情况来看,我还是比较满意的(虽然还是有很多bug),实现了要求的功能,还增加了自己的创意。不过还是存在代码不够规范的问题,不同文件、不同类糅杂在一起,以至于我自己都不清楚我的代码文件是怎么组织的。
在完成这次实验的过程中,最大的困难是编写删除操作的代码。我会思考了很久才想出一种很复杂的方法,这也带来了大量的代码和bug,不过好在还是写出来了。但在跟其他同学交流之后,似乎他们的方法更为简单,而我的方法理论上在性能方面会更优秀(我也不太确定),为了偷个懒我也没有改。
还有一个遗憾是没有用到汇编语言。事实上大部分代码是用c++编写的,还用到了stl和linux的各种头文件里的很多内容,可能会导致代码的可移植性有点差。
这次实验的收获也是很明显的,我锻炼了编写较大规模程序的能力,对文件系统和操作系统有了更深入的了解,也激发了我进一步学习操作系统的兴趣。
总的来说,这次实验完成的十分艰难,但也是收获满满,有一些做的不错的地方,也有不少改进的空间。希望在接下来的课程中也能有这么有趣的实验。