import torch as t import torchvision as tv import torchvision.transforms as transforms from torchvision.transforms import ToPILImage show=ToPILImage() #show用于将Tensor对象转化为图片,以便于观察结果 transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]) #transform 用于对输入图像进行预处理 trainset=tv.datasets.CIFAR10(root='/home/cy/data/',train=True,download=True,transform=transform) trainloader=t.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=2) #用trainloader加载训练数据,batch_size=4说明一个batch是4张图片,num_worker=2说明用两个线程 testset=tv.datasets.CIFAR10('/home/cy/data/',train=False,download=True,transform=transform) testloader=t.utils.data.DataLoader(testset,batch_size=4,shuffle=False,num_workers=2) classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
defforward(self,x): x=F.max_pool2d(F.relu(self.conv1(x)),(2,2)) x=F.max_pool2d(F.relu(self.conv2(x)),2)# 这里的2跟(2,2)的效果是一样的 x=x.view(x.size()[0],-1) x=F.relu(self.fc1(x)) x=F.relu(self.fc2(x)) x=self.fc3(x) return x
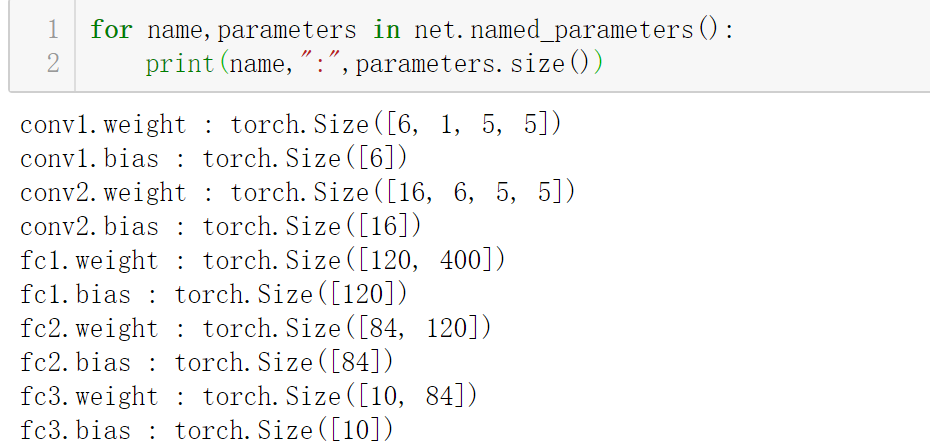
net=Net() print(net)
定义一个损失函数和优化器
1 2 3
from torch import optim criterion = nn.CrossEntropyLoss() optimizer=optim.SGD(net.parameters(),lr=0.001,momentum=0.9)
开始训练:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
from torch.autograd import Variable for epoch in range(2): runnint_loss=0.0 for i,data in enumerate(trainloader,0): inputs,labels=data inputs,labels=Variable(inputs),Variable(labels) #注意要将输入数据转化成Variable类型,不然无法训练 optimizer.zero_grad() outputs=net(inputs) loss=criterion(outputs,labels) loss.backward() optimizer.step() runnint_loss+=loss.item() if i%2000==1999: print("[%d,%5d] loss: %3f"%(epoch+1,i+1,runnint_loss/2000)) runnint_loss=0.0 print("Finish trainning")
查看第一个batch的数据和标签:
1 2 3 4
dataiter=iter(testloader) images,labels=dataiter.next() print("实际的label:"," ".join("%08s"%classes[labels[j]] for j in range(4))) show(tv.utils.make_grid(images/2-0.5)).resize((400,100))
查看它们的预测结果:
1 2 3
outputs=net(Variable(images)) _,predicted=t.max(outputs.data,1) print("预测结果:","".join("%8s"%classes[predicted[j]] for j in range(4)))
查看总正确率:
1 2 3 4 5 6 7 8 9 10 11
correct=0 total=0 for data in testloader: images,labels=data outputs=net(Variable(images)) _,predicted=t.max(outputs.data,1) #output.data是一个数组,max返回两个值,第一个是最大值,第二个是最大值所在的位置 total+=labels.size(0) correct+=(predicted==labels).sum() #根据最大值所在的位置是否跟labels相等可以判断分类是否正确 print("正确率为:%d %%"%(100*correct/total))