Pthread学习笔记2
临界区问题
当多个线程同时修改同一个内存地址时,可能会出现奇奇怪怪的问题。我们根据下面的公式编写一个计算π的程序: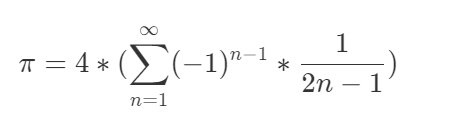
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| #include<pthread.h>
#include<stdio.h>
#include<stdlib.h>
#include<sys/time.h>
int thread_count,n;
double sum;
void* Thread_sum(void* rank){
long my_rank=(long)rank;
double factor;
long long i;
long long my_n=n/thread_count;
long long my_first_i=my_n*my_rank;
long long my_last_i=my_first_i+my_n;
if(my_first_i%2==0){
factor=1.0;
}
else factor=-1.0;
for(i = my_first_i;i<my_last_i;i++,factor=-factor){
sum+=factor/(2*i+1);
}
return NULL;
}
int main(int argc,char** argv){
if(argc!=3)abort();
long thread;
pthread_t* thread_handles;
thread_count=strtol(argv[1],NULL,10);
printf("ans: %f\n",sum);
n=strtol(argv[2],NULL,10);
struct timeval tv,tv2;
gettimeofday(&tv,NULL);
thread_handles=malloc(thread_count*sizeof(pthread_t));
for(thread=0;thread<thread_count;thread++)pthread_create(&thread_handles[thread],NULL,Thread_sum,(void*)thread);
for(thread=0;thread<thread_count;thread++)pthread_join(thread_handles[thread],NULL);
gettimeofday(&tv2,NULL);
printf("ans: %.8f\n",4*sum);
printf("%d\n",tv2.tv_sec*1000000 + tv2.tv_usec - tv.tv_sec*1000000 - tv.tv_usec);
return 0;
}
|
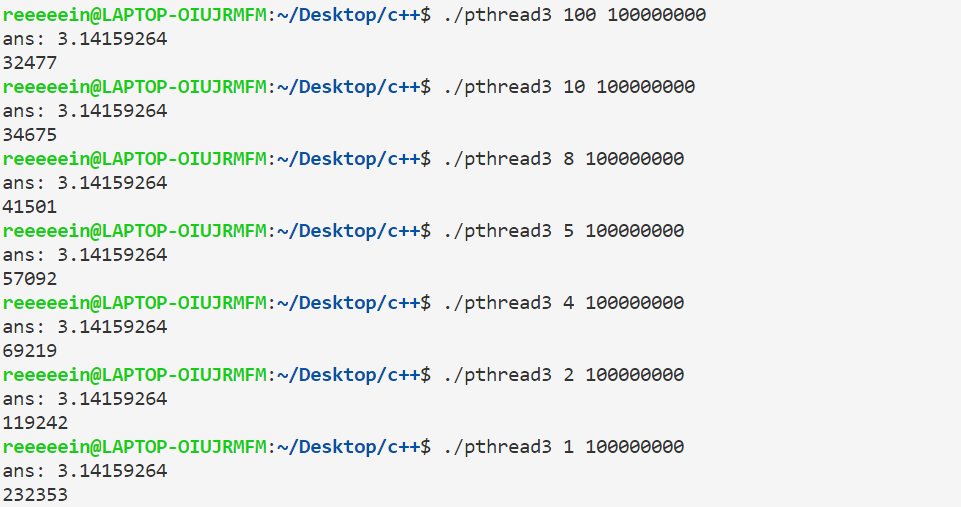
执行代码,当线程数大于1的时候会发现,程序输出的结果是不确定的,而且误差也较1个线程的情况大,甚至运行时间也是较长:
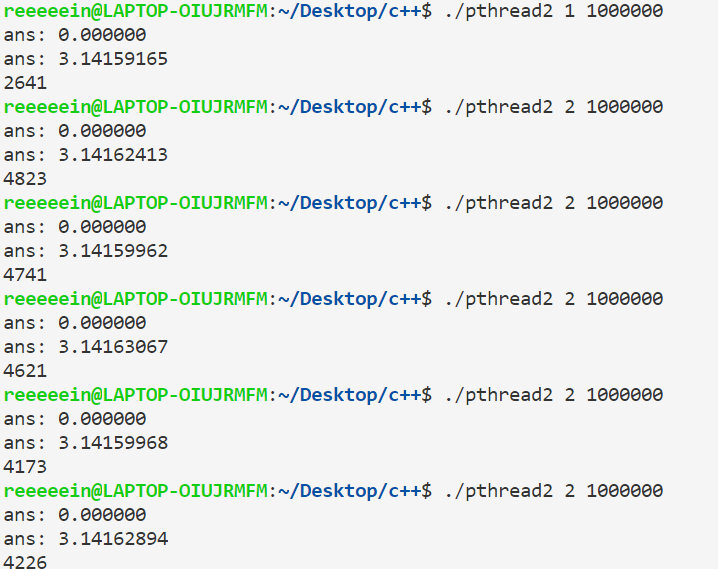
这种情况被称为临界区问题,当0号线程把sum取到寄存器并执行运算的时候,1号进程也可能同时把sum取到寄存器,然后0号进程把结果写回内存,随后1号进程也把结果写回内存。这样就导致0号进程的计算结果被覆盖掉了,我们称
这样更新共享资源的语句为一个临界区。当多个线程尝试更新一个共享资源时,结果可能是无法预测的。更一般地,当多个线程都要访问共享变量或共享文件这样的共享资源时,如果有一个线程执行了更新操作,就可能产生错误,我们称之为竞争条件。
临界区问题可以用忙等待、互斥量和信号量等方法来解决。
忙等待
一种解决方法是设置一个标记变量,用于指明临界区可以被哪个线程执行,该执行完之后修改这个标记变量,而不能执行临界区的线程必须一直处于忙等待状态。
我们可以将代码修改成这样:
1
2
3
| while(flag!=my_rank);
sum+=factor/(2*i+1);
flag=(flag+1)%thread_count;
|
flag是我们说到的标记变量,当flag==当前线程号时,可以执行临界区,否则必须处于忙等待状态。执行完之后要修改flag。
运行结果如下:
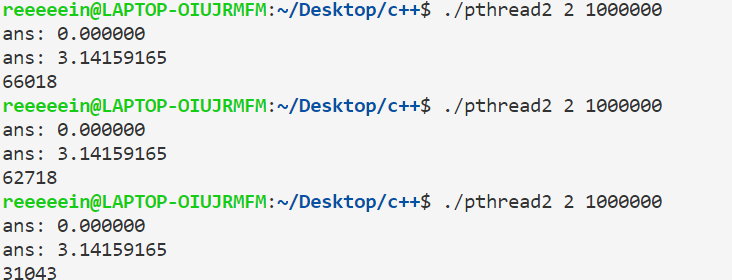
可以看到,结果是正确了,但运行速度满了很多,甚至比单线程的情况还慢。
当然,由于临界区只能被串行执行,我们应该尽量减少临界区执行的次数,比如,我们可以把Thread_sum函数修改成这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| void* Thread_sum(void* rank){
long my_rank=(long)rank;
double my_sum=0;
double factor;
long long i;
long long my_n=n/thread_count;
long long my_first_i=my_n*my_rank;
long long my_last_i=my_first_i+my_n;
if(my_first_i%2==0){
factor=1.0;
}
else factor=-1.0;
for(i = my_first_i;i<my_last_i;i++,factor=-factor){
my_sum+=factor/(2*i+1);
}
while(flag!=my_rank);
sum+=my_sum;
flag=(flag+1)%thread_count;
return NULL;
}
|
用一个局部变量来代替sum变量,这样循环的过程中就不会有临界区。
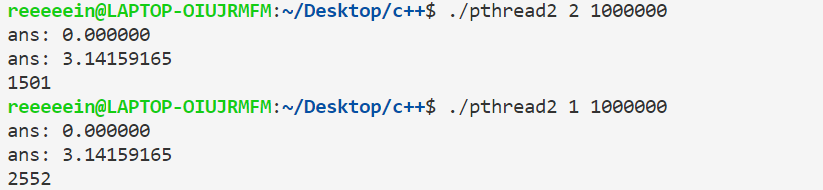
运行结果正确,速度上也有提升。
使用忙等待还会有一个问题:
考虑一个最多可以同时执行2个线程的计算机,我们使用忙等待的方法编写一个5个线程的pthreads程序。假设开始时,操作系统运行0号线程和1号线程,这是没有问题的,此时2,3,4三个线程被挂起。然后假设0号线程运行结束,操作系统将其挂起,然后调度3号线程。由于操作系统的线程调度是随机的,它完全不知道此时只有2号线程能进入临界区,所以3号线程只能一直处于忙等待状态,浪费了时间。
所以,当线程数量大于计算机能同时运行的线程数时,使用忙等待的方法可能会产生问题。
互斥量
由于处于忙等待的线程会持续地占用CPU资源,所以忙等待并不是一个特别理想的解决临界区问题的方案。我们可以使用互斥量和信号量。
互斥量是互斥锁的简称,是一个特殊类型的变量,它可以保证每次只有一个线程能进入临界区。
互斥量的变量类型是pthread_mutex_t,必须调用 pthread_mutex_init()函数进行初始化。
当线程执行到临界区前面时,应该调用pthread_mutex_lock()函数。如果此时临界区已经被加了锁(即已经有其他线程执行到了这里),则它会被卡在临界区外等待;否则它会进入临界区,并把临界区加锁。
当临界区被执行完,线程要用pthread_mutex_unlock函数把临界区解锁。此时,系统会从其他等待的线程选出一个进入临界区。如果有多个等待的线程,操作系统选择哪个线程是随机的的。
互斥量使用完之后要用pthread_mutex_destroy函数将其销毁。
互斥量的示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| #include<pthread.h>
#include<stdio.h>
#include<stdlib.h>
#include<sys/time.h>
int thread_count,n;
double sum;
int flag;
pthread_mutex_t mutex;
void* Thread_sum(void* rank){
long my_rank=(long)rank;
double my_sum=0;
double factor;
long long i;
long long my_n=n/thread_count;
long long my_first_i=my_n*my_rank;
long long my_last_i=my_first_i+my_n;
if(my_first_i%2==0){
factor=1.0;
}
else factor=-1.0;
for(i = my_first_i;i<my_last_i;i++,factor=-factor){
my_sum+=factor/(2*i+1);
}
pthread_mutex_lock(&mutex);
sum+=my_sum;
pthread_mutex_unlock(&mutex);
return NULL;
}
int main(int argc,char** argv){
if(argc!=3)abort();
long thread;
pthread_t* thread_handles;
thread_count=strtol(argv[1],NULL,10);
n=strtol(argv[2],NULL,10);
pthread_mutex_init(&mutex,NULL);
struct timeval tv,tv2;
gettimeofday(&tv,NULL);
thread_handles=malloc(thread_count*sizeof(pthread_t));
for(thread=0;thread<thread_count;thread++)pthread_create(&thread_handles[thread],NULL,Thread_sum,(void*)thread);
for(thread=0;thread<thread_count;thread++)pthread_join(thread_handles[thread],NULL);
free(thread_handles);
pthread_mutex_destroy(&mutex);
gettimeofday(&tv2,NULL);
printf("ans: %.8f\n",4*sum);
printf("%d\n",tv2.tv_sec*1000000 + tv2.tv_usec - tv.tv_sec*1000000 - tv.tv_usec);
return 0;
}
|
运行结果:
信号量
信号量(semaphore)可以认为是一种特殊类型的unsigned int,它的类型是sem_t。信号量可以赋值为0,1,……。大多数情况下,我们只用0和1两个值。这种只有0和1值的信号量也称为二元信号量。0对应上了锁的互斥量,1对应没上锁的互斥量。
初始化信号量的方法是调用sem_init(),它的原型是:
1
| int sem_init(sem_t* a,int b,int c);
|
其中第二个参数直接置为0就可以了,第三个参数是初始值。
如果我们要用信号量来解决临界区问题,可以先创建一个全局信号量,初始值为1。在临界区前调用sem_wait()函数,这个函数的意义是:如果信号量为0则阻塞;如果是非0值则减1然后进入临界区。临界区执行完之后,调用sem_post()函数将信号量置为1。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| #include<pthread.h>
#include<stdio.h>
#include<stdlib.h>
#include<semaphore.h>//注意要加这个头文件
#include<sys/time.h>
int thread_count,n;
double sum;
int flag;
sem_t my_semaphore;
void* Thread_sum(void* rank){
long my_rank=(long)rank;
double my_sum=0;
double factor;
long long i;
long long my_n=n/thread_count;
long long my_first_i=my_n*my_rank;
long long my_last_i=my_first_i+my_n;
if(my_first_i%2==0){
factor=1.0;
}
else factor=-1.0;
for(i = my_first_i;i<my_last_i;i++,factor=-factor){
my_sum+=factor/(2*i+1);
}
sem_wait(&my_semaphore);
sum+=my_sum;
printf("Thread %d\n",my_rank);
sem_post(&my_semaphore);
return NULL;
}
int main(int argc,char** argv){
if(argc!=3)abort();
long thread;
pthread_t* thread_handles;
thread_count=strtol(argv[1],NULL,10);
n=strtol(argv[2],NULL,10);
sem_init(&my_semaphore,0,1);
struct timeval tv,tv2;
gettimeofday(&tv,NULL);
thread_handles=malloc(thread_count*sizeof(pthread_t));
for(thread=0;thread<thread_count;thread++)pthread_create(&thread_handles[thread],NULL,Thread_sum,(void*)thread);
for(thread=0;thread<thread_count;thread++)pthread_join(thread_handles[thread],NULL);
free(thread_handles);
gettimeofday(&tv2,NULL);
printf("ans: %.8f\n",4*sum);
printf("%d\n",tv2.tv_sec*1000000 + tv2.tv_usec - tv.tv_sec*1000000 - tv.tv_usec);
return 0;
}
|
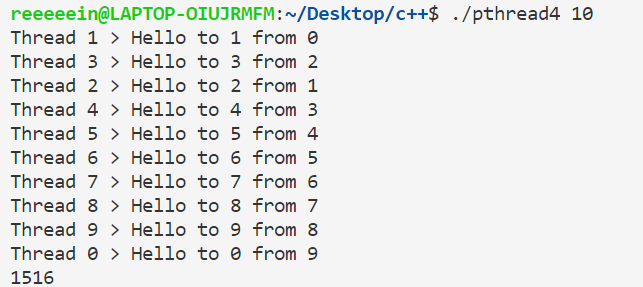
使用信号量还可以控制线程执行的顺序,如发送消息问题。我们可以给每个线程分配一个信号量,初始化为0,给每个线程一个char*,指向收到的消息。每一个线程把消息放到下一个线程后将下一个线程的信号量置为1,然后等待上一个线程的消息。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| #include<pthread.h>
#include<stdio.h>
#include<stdlib.h>
#include<semaphore.h>
#include<sys/time.h>
#define MSG_MAX 100
int thread_count,n;
double sum;
int flag;
pthread_mutex_t mutex;
char** messages;
sem_t* semaphores;
void* Thread_sum(void* rank){
long my_rank=(long)rank;
long dest=(my_rank+1)%thread_count;
char* my_msg=malloc(MSG_MAX*sizeof(char));
sprintf(my_msg,"Hello to %ld from %ld",dest,my_rank);
messages[dest]=my_msg;
sem_post(&semaphores[dest]);
sem_wait(&semaphores[my_rank]);
printf("Thread %ld > %s\n",my_rank,messages[my_rank]);
}
int main(int argc,char** argv){
if(argc!=2)abort();
long thread;
pthread_t* thread_handles;
thread_count=strtol(argv[1],NULL,10);
semaphores=(sem_t*)malloc(thread_count*sizeof(sem_t));
messages=(char**)malloc(thread_count*sizeof(char*));
struct timeval tv,tv2;
gettimeofday(&tv,NULL);
thread_handles=malloc(thread_count*sizeof(pthread_t));
for(thread=0;thread<thread_count;thread++)pthread_create(&thread_handles[thread],NULL,Thread_sum,(void*)thread);
for(thread=0;thread<thread_count;thread++)pthread_join(thread_handles[thread],NULL);
free(thread_handles);
pthread_mutex_destroy(&mutex);
gettimeofday(&tv2,NULL);
printf("ans: %.8f\n",4*sum);
printf("%d\n",tv2.tv_sec*1000000 + tv2.tv_usec - tv.tv_sec*1000000 - tv.tv_usec);
return 0;
}
|
结果如下所示:
但如果我们把sem_wait那一行去掉,会出现这样的变化:
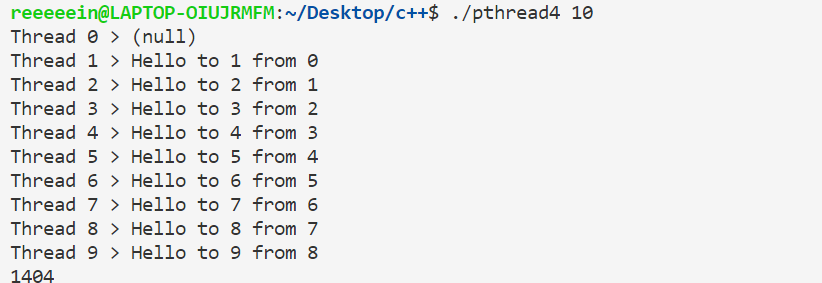
第0号线程没有收到消息的时候就调用printf函数,自然就得不到想要的结果。
像上面这种一个线程需要等待另一个线程执行某种操作的同步方式,有时称为生产者-消费者同步模型。