并行与分布式计算作业3
题目要求
利用LLVM (C、C++)或者Soot (Java)等工具检测多线程程序中潜在的数据竞争以及是否存在不可重入函数,给出案例程序并提交分析报告。
概述
用pthreads编写一个简单的并行程序,用附带了ThreadSanitizer的clang对代码进行编译,在终端运行,查看数据竞争情况。再根据ThreadSanitizer的输出结果对代码进行修改,通过忙等待、互斥量和信号量等方法对临界区加锁,消除数据竞争。
编写一个检测程序中是否存在不可重入函数的程序,它读取一个IR文件,判断其中的每一个函数是否是不可重入的。
检测数据竞争
根据
$$\pi=4(\sum_{n=1}^{\infty}(-1)^{n-1}\frac{1}{2n-1})$$
编写一个计算$\pi$值的并行程序,代码见code1.c:
通过命令行参数得到线程数量和要计算的范围。在第33行创建多个线程,每个线程负责计算一部分内容,把结果累加到全局变量sum上。由于多个线程是并行执行的,且会对sum进行修改,所以会出现问题。不用ThreadSanitizer时,程序运行结果如下:
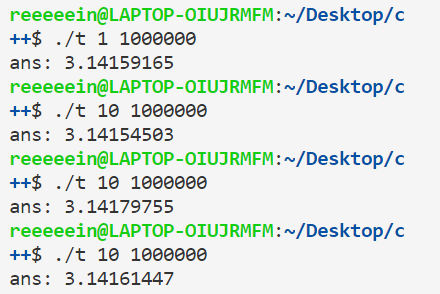
可以看到,每次运行结果都不一样,有时偏大有时偏小,说明数据竞争现象确实存在。
用ThreadSanitizer检测,结果如下:
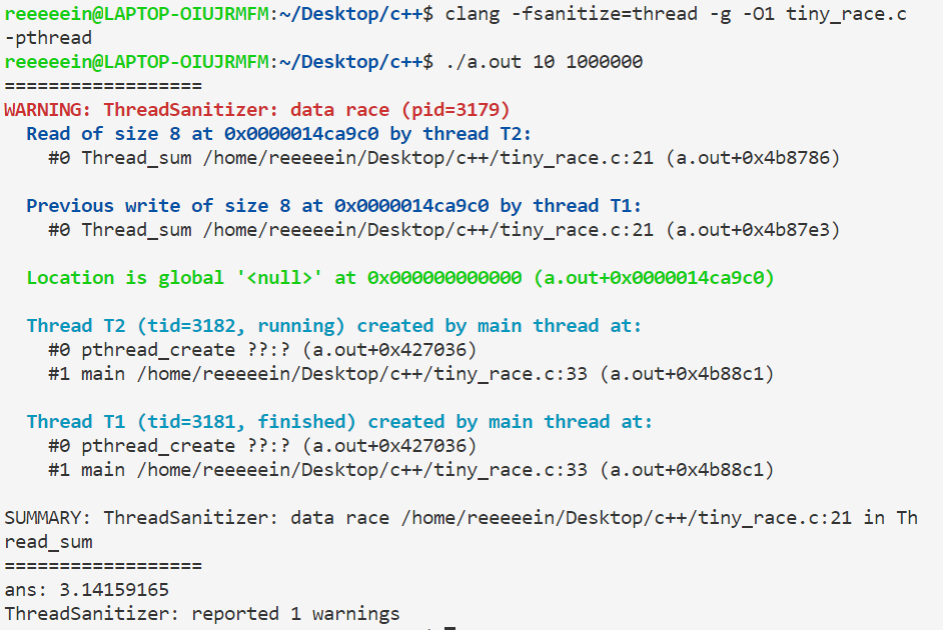
可以看到,运行结果显示存在data race,在第21行,刚好就是:
1 | sum+=factor/(2*i+1); |
一个很自然的想法是,给每个线程创建一个局部变量,把要计算的值加到这个局部变量上,最后再对所有线程求一次和。只需将Thread_sum函数修改为这样:
1 | void* Thread_sum(void* rank){ |
这样看似正常,但运行后发现,第24行仍然是多个线程同时修改一个全局变量,仍然存在数据竞争现象:
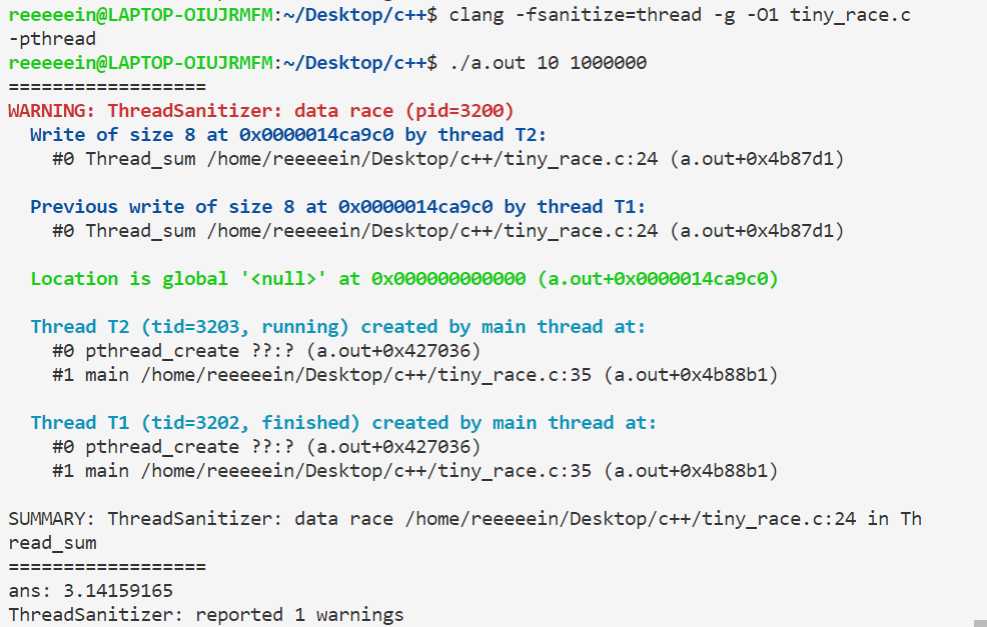
解决数据竞争
尝试用忙等待、互斥量和信号量来解决数据竞争问题。
忙等待
忙等待就是设置一个标记变量,用于指明临界区可以被哪个线程执行,该执行完之后修改这个标记变量,而不能执行临界区的线程必须一直处于忙等待状态。
这只用定义一个flag,再对上面的第24行修改为:
1 | while(flag!=my_rank); |
完整代码保存在code2.c
ThreadSanitizer似乎不支持用忙等待的方法对临界区加锁:
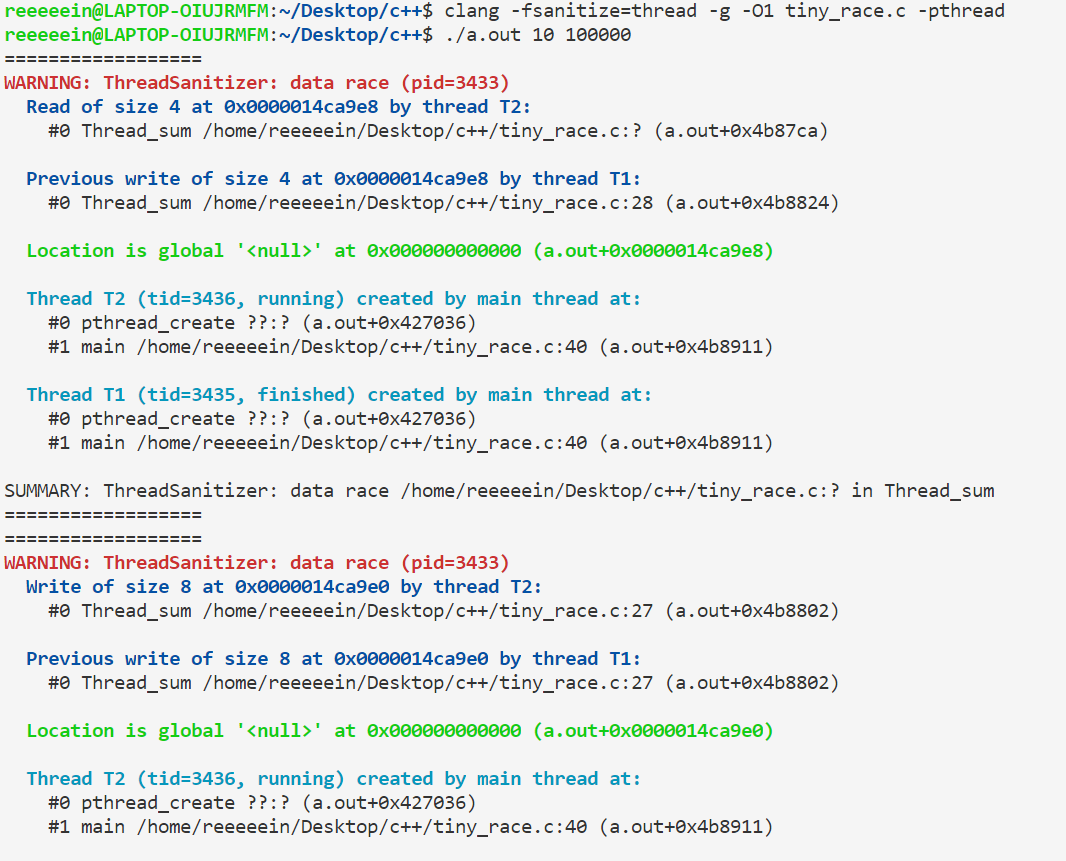
互斥量
互斥量能保证同一时间只有一个线程在执行临界区的代码,其他线程只能等待。等当前线程执行完之后,会从等待的线程中随机选一个进入临界区。
这只用定义一个互斥量mutex,再将临界区代码修改为:
1 | pthread_mutex_lock(&mutex); |
完整代码保存在code3.c
用ThreadSanitizer测试,结果正常,没有warning:
信号量
信号量(semaphore)可以认为是一种特殊类型的unsigned int,它的类型是sem_t。信号量可以赋值为0,1,……。大多数情况下,我们只用0和1两个值。这种只有0和1值的信号量也称为二元信号量。0对应上了锁的互斥量,1对应没上锁的互斥量。
如果我们要用信号量来解决临界区问题,可以先创建一个全局信号量,初始值为1。在临界区前调用sem_wait()函数,这个函数的意义是:如果信号量为0则阻塞;如果是非0值则减1然后进入临界区。临界区执行完之后,调用sem_post()函数将信号量置为1。好像跟互斥量没啥区别
这也只用定义一个信号量my_semaphore,在main函数里初始化,再将临界区代码修改为:
1 | sem_wait(&my_semaphore); |
完整代码见code4.c
测试一下,也很正常:

检测不可重入函数
利用clang可以生成c语言程序对应的中间表示,下面这个函数:
1 | void C(int a){ |
会被转化为
1 | define void @C(i32) #0 { |
我们不关心其他的内容,只需要知道:
函数定义以“define”开始,这一行的第一个 ‘@’ 和 ‘(‘ 之间的字符串是函数的名字。
调用一个其他函数会以 “call” 开始, 这一行的第一个 ‘@’ 和 ‘(‘ 之间的字符串是被调用函数的名字。
访问一个全局变量时会用到 ‘@’ ,访问其他变量会用到 ‘%’ 。
此外,被其他函数调用但没有在程序中定义的函数,像printf()函数等,都默认为不可重入函数。
知道了这些,就可以写一个程序来检测程序中的不可重入函数了。做法很简单,把函数理解为一个点,把调用关系理解为边,A调用了B就连一条B->A的边。然后将访问了全局变量的函数和在程序中没有给出定义的函数标记为不可重入函数,从这些 “原生的” 不可重入函数开始进行深度优先搜索,凡是访问到的点都是不可重入函数。深度优先搜索的示例代码如下:
1 | void dfs(int u){ |
完整代码见code5.cpp
测试
编写一个test.c,里面有几个函数调用来调用去,如下图所示:
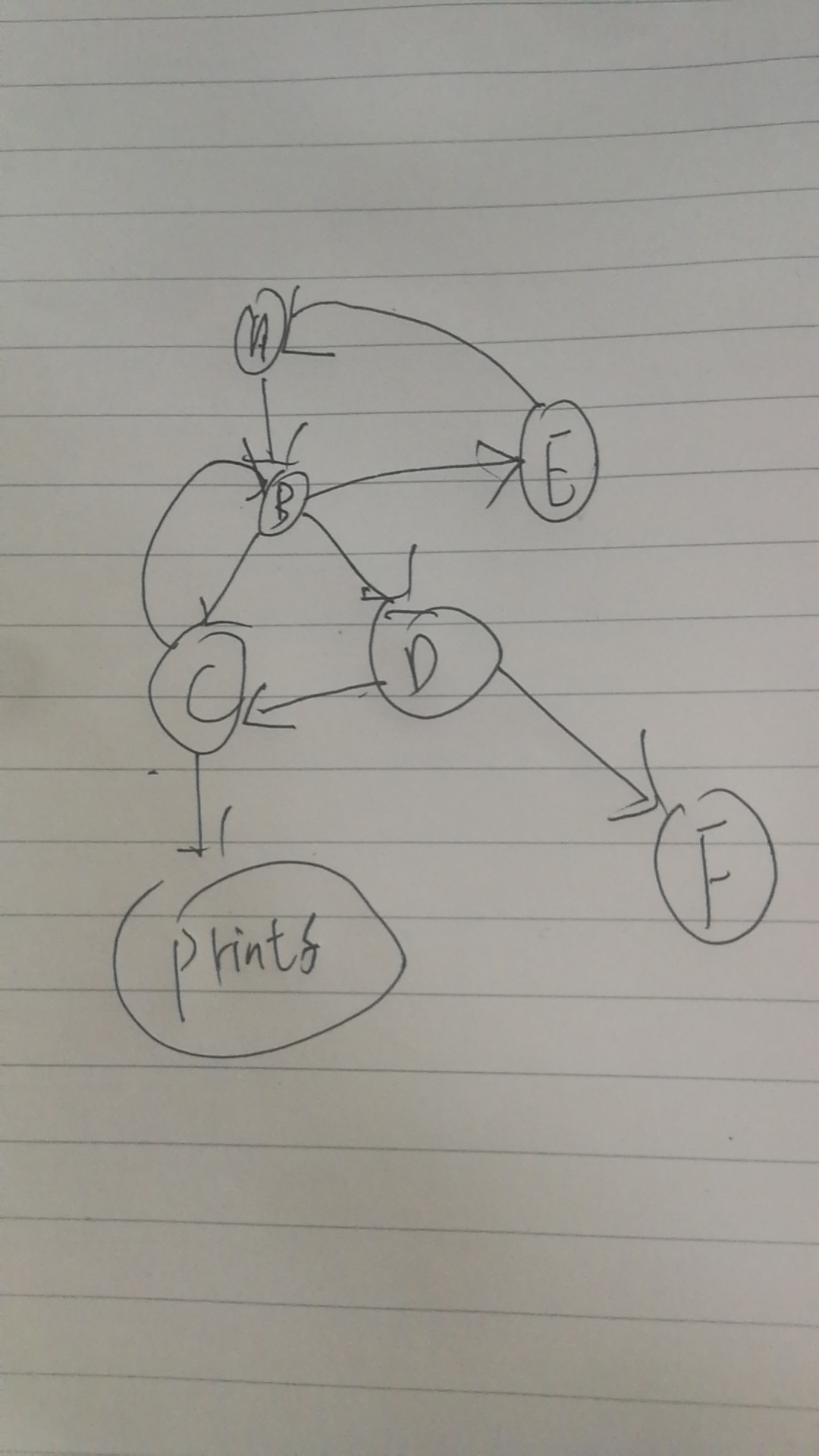
用clang生成中间代码:
1 | clang -O0 -S -emit-llvm ./test/test.c -o input.ll |
进行检测,输出如下:

结果符合预期。
总结
用ThreadSanitizer可以方便地检测多线程中存在的数据竞争问题,检测到临界区后,可以用互斥量和信号量对它进行加锁。利用llvm可以生成程序的中间代码,然后可以检测其中是否有不可重入函数。
这次实验完成的比较简单,主要是因为之前学过一点pthread,还写了篇学习笔记,于是直接把代码和博客的内容拿过来用了(抄自己的博客不算抄吧)。检测不可重入函数稍微有点复杂,不过只要对llvm的中间代码有了基本的了解,学过一些图论算法,解决起来也不算困难。
一个比较大的收获是学会了使用ThreadSanitizer来检查数据竞争,大大方便了以后编写多线程程序。